逻辑回归的推导及实现
摘要
本文中,我们先推导了逻辑回归的公式,梯度下降过程;然后使用torch从零开始实现了一个LR model,接着使用torch自带函数来简化实现过程;然后在二分类数据集上演示了模型的训练效果。 最后我们介绍了两种在LR模型上使用多分类的思想,分别是ONE-vs-ALL和ONE-vs-ONE,并实现了这两种算法,在三分类数据集上测试了这两种方法,从结果来看效果都非常好。
公式推导
线性回归
线性回归的表达式是:
逻辑回归
为了让模型能够处理分类问题,我们将线性回归的输出再做为输入送到sigmoid函数中

将线性回归的表达式带入即可得逻辑回归的表达式:
从上图可以看出,逻辑回归在定义域大于0时取值接近1,而在定义域小于0是取值接近0,我们可利用该特性来处理二分类问题(多分类的情况后文会介绍处理策略),对于某个二分类问题,也就是
逻辑回归的损失函数
有了概率表达式我们就可以来计算损失函数了。 由于
上面的公式可以统一起来表示为:
对于某个数据集,假设我们一共采集到
由于连乘比较复杂,我们对该表达式取对数,同时,这里的
这便是我们的损失函数。
梯度求解
为了使用梯度下降优化模型,还需要求出损失函数的梯度,下面我们来求解上述
这里,对
梯度下降(GD)与随机梯度下降(SGD)
有了梯度之后就可以使用梯度来更新参数了,对于梯度下降来说,更新公式为
式中
对于随机梯度下降来说,每次给梯度增加一个服从正态分布
从零实现逻辑回归
现在我们自己来实现逻辑回归。
准备工作
首先我们需要安装两个python包:
pip install pytorch matplotlib
然后引入代码包:
import torch
import matplotlib.pyplot as plt
为了验证模型效果,我们还需要准备一份数据集,这里为了简单起见,我们自己生成一份数据集:
def load_data_n2(size):
"""加载数据:生成虚拟二分类数据"""
num_featurs = 2
X0 = torch.normal(2, 1, (size, num_featurs))
y0 = torch.zeros((size, 1))
X1 = torch.normal(-2, 1, (size, num_featurs))
y1 = torch.ones((size, 1))
X = torch.cat((X0, X1), dim=0)
y = torch.cat((y0, y1), dim=0)
return X, y
num_samples = 1000
X_train, y_train = load_data(num_samples)
X_test, y_test = load_data(num_samples//3)
# 添加偏置b: X = [1 X]
X_train = torch.cat([torch.ones((X_train.shape[0], 1)), X_train], dim=1)
X_test = torch.cat([torch.ones((X_test.shape[0], 1)), X_test], dim=1)
# 可视化数据,二维
plt.scatter(X_train[:,1], X_train[:,2], c=y_train.numpy(), s=60, lw=0, cmap='RdYlGn', alpha=0.5)
plt.scatter(X_test[:,1], X_test[:,2], c=y_test.numpy(), s=10, lw=1, alpha=1)
plt.show()
生成的数据集如下:
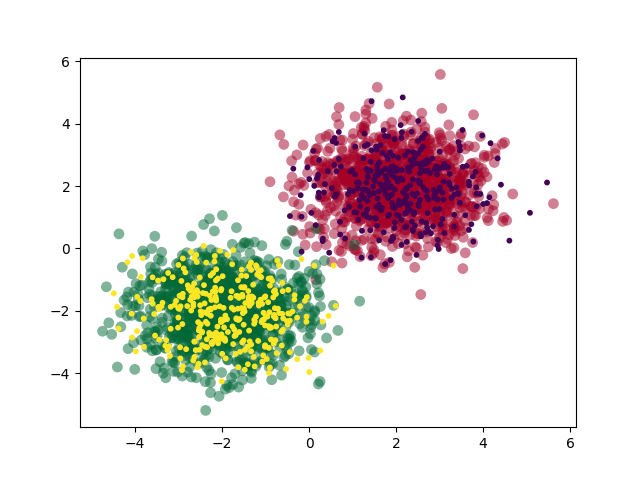
为了可视化模型的结果,我们还需要实现两个函数,一个用来绘制损失函数和准确度,另一个用来绘制决策面:
def plot_loss_acc(epochs, loss, acc):
"""绘制损失函数和准确率曲线"""
plt.figure('acc & loss')
plt.subplot(221)
plt.plot(epochs, acc, color='r', label='acc')
plt.xlabel('epochs')
plt.ylabel('acc')
plt.title("acc")
plt.subplot(222)
plt.plot(epochs, loss, color='r', label='loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.title("loss")
return plt
def plot_decision_boundary(model, X, y, X_test=None, y_test=None):
"""绘制决策面"""
x_min, x_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
y_min, y_max = X[:, 2].min() - 0.5, X[:, 2].max() + 0.5
h = 0.01
# 绘制网格
xs, ys = torch.meshgrid(torch.arange(x_min, x_max, h), torch.arange(y_min, y_max, h), indexing='xy')
# 生成与网格上所有点对应的分类结果
n = len(xs.ravel())
zs = model.predict(torch.cat([torch.ones((n, 1)), xs.ravel().reshape((-1, 1)), ys.ravel().reshape((-1, 1))], dim=1)).reshape(xs.shape)
# 绘制contour
plt.figure('decision boundary')
acc = torch.tensor(0.)
if X_test is not None:
acc = model.accuracy(X_test, y_test)
plt.title(f'Accuracy:{acc.numpy()*100:.2f}%')
plt.contourf(xs, ys, zs, alpha=0.2)
plt.scatter(X[:, 1], X[:, 2], c=y.numpy(), s=50, lw=0, cmap='RdYlGn', alpha=0.5)
if X_test is not None and y_test is not None:
plt.scatter(X_test[:, 1], X_test[:, 2], c=y_test.numpy(), s=20, lw=0, alpha=1.0)
return plt
实现主要函数
现在我们来实现
def sigmoid(X):
"""sigmoid函数"""
return 1 / (1 + torch.exp(-X))
接着实现梯度下降:
def gradient_descent(W, X, y, lr=0.1):
"""梯度下降优化"""
y_pred = sigmoid(X @ W)
gradient = -torch.sum((y-y_pred)*X, dim=0).reshape((-1, 1))
W -= lr*gradient
return W
计算损失函数:
def loss(W, X, y):
"""损失函数"""
y_pred = self.sigmoid(X @ W)
log1 = torch.log(y_pred + 1e-10)
log2 = torch.log(1 - y_pred + 1e-10)
return -torch.mean(y*log1 + (1-y)*log2)
类的封装
上面我们单独把几个关键函数实现了,现在我们用面向对象的思想把这些功能封装为一个类(借鉴sklearn的模式):
class LR:
def __init__(self):
self.W = None # 权重
self.lr = 0.1
self.num_epochs = 1
self.losses = []
self.acc = []
self.epochs = []
def sigmoid(self, X):
"""sigmoid函数"""
return 1 / (1 + torch.exp(-X))
def gradient_descent(self, X, y):
"""梯度下降优化"""
y_pred = self.sigmoid(X @ self.W)
gradient = -torch.sum((y-y_pred)*X, dim=0).reshape((-1, 1))
self.W -= self.lr*gradient
return self.W
def loss(self, X, y):
"""损失函数"""
y_pred = self.sigmoid(X @ self.W)
log1 = torch.log(y_pred + 1e-10)
log2 = torch.log(1 - y_pred + 1e-10)
return -torch.sum(y*log1 + (1-y)*log2)
def accuracy(self, X, y):
"""测试集准确率"""
return torch.sum(self.predict(X) == y) / len(y)
def fit(self, X, y, num_epochs=100, lr=0.1, make_cache=True, echo=True):
"""训练模型"""
self.lr = lr
self.num_epochs = num_epochs
self.W = torch.normal(0, 1, (X.shape[1], 1))
for epoch in range(self.num_epochs):
self.gradient_descent(X, y)
if epoch % 10 == 0:
acc = self.accuracy(X, y)
l = self.loss(X_train, y_train)
if make_cache:
self.losses.append(l)
self.acc.append(acc)
self.epochs.append(epoch)
if echo:
print(f'epoch:{epoch+1}, acc:{acc:.4f}, loss:{l:.4f}')
return self
def predict(self, X):
"""预测样本标签"""
y_pred = self.sigmoid(X @ self.W)
y_pred[y_pred >= 0.5] = 1.0
y_pred[y_pred < 0.5] = 0.0
return y_pred
在上面的类中,我们还实现了几个额外的函数,fit函数用来实现模型训练过程,predict函数用来进行预测,accuracy函数用来计算模型正确率,现在让我们来运行一下这个模型:
# 准备数据集
num_samples = 1000
X_train, y_train = load_data_n2(num_samples)
X_test, y_test = load_data_n2(num_samples//3)
# 添加偏置b: X = [1 X]
X_train = torch.cat([torch.ones((X_train.shape[0], 1)), X_train], dim=1)
X_test = torch.cat([torch.ones((X_test.shape[0], 1)), X_test], dim=1)
# 可视化数据,二维
plt.figure()
plt.scatter(X_train[:,1], X_train[:,2], c=y_train.numpy(), s=60, lw=0, cmap='RdYlGn', alpha=0.5)
plt.scatter(X_test[:,1], X_test[:,2], c=y_test.numpy(), s=10, lw=1, alpha=1)
# 训练模型
model = LR()
model.fit(X_train, y_train, num_epochs=1000, lr=0.001, make_cache=True, echo=False)
# 模型结果可视化
acc = model.accuracy(X_test, y_test)
print('LR model 测试集准确率:', acc.numpy())
plot_loss_acc(model.epochs, model.losses, model.acc)
plot_decision_boundary(model, X_train, y_train, X_test=X_test, y_test=y_test)
plt.show()
模型的验证集正确率和损失函数的变化如下:
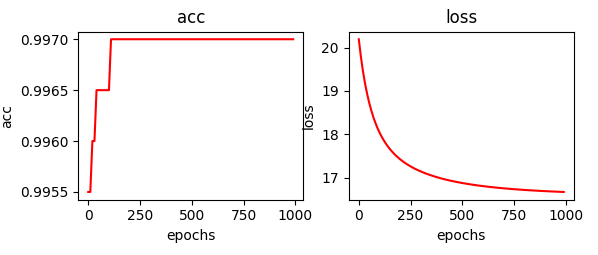
模型绘制的决策面如下:

从上图可见,模型对该数据集的分类准确率非常好,达到了99.85%。
简化实现逻辑回归
现在让我们用torch内置的一些函数来简化这个实现过程: 首先定义网络结构,LR模型其实就是只有一个输入层一个输出层中间无任何隐藏层的全连接网络,激活函数选用sigmoid:
class LRModel(torch.nn.Module):
"""用torch简化实现LR model"""
def __init__(self, num_features) -> None:
super(LRModel, self).__init__()
self.lr = torch.nn.Sequential(torch.nn.Linear(num_features, 1, bias=False), # 这里我们会自己处理bias,所以无需模型拟合
torch.nn.Sigmoid())
def forward(self, X):
"""前向传播"""
return self.lr(X)
然后封装为类:
class LRNet:
"""torch 简化实现LR训练过程"""
def __init__(self):
self.net = LRModel(2+1) # 这里加了偏置之后样本特征增加一列1
self.epochs = []
self.losses = []
self.acc = []
def predict(self, X):
"""预测"""
y_pred = self.net(X)
y_pred[y_pred >= 0.5] = 1.0
y_pred[y_pred < 0.5] = 0.0
return y_pred.detach()
def accuracy(self, X, y):
"""计算模型准确率"""
return (torch.sum(self.predict(X) == y) / len(y)).detach()
def fit(self, X, y, num_epochs=10, lr=0.1):
"""训练模型"""
criterion = torch.nn.BCELoss() # 损失函数
optimizer = torch.optim.SGD(self.net.parameters(), lr) # 随机梯度下降优化器
for epoch in range(num_epochs):
y_hat = self.net(X) # 前向传播
loss = criterion(y_hat, y) # 计算损失
optimizer.zero_grad() # 反向传播更新梯度之前需要先清空之前的梯度
loss.backward() # 使用损失函数的梯度反向传播
optimizer.step() # 更新梯度
if epoch % 10 == 0:
self.epochs.append(epoch)
self.losses.append(loss.detach().numpy())
self.acc.append(self.accuracy(X, y).numpy())
return self
从上图可见,torch自带的损失函数及优化器帮我们简化了模型的实现,无需自己重新定义。 训练一下该模型:
# 简化实现版
lr = LRNet()
lr.fit(X_train, y_train, num_epochs=100, lr=0.01)
print('LR(torch版) model 测试集准确率:', acc.numpy())
plot_loss_acc(lr.epochs, lr.losses, lr.acc)
plot_decision_boundary(lr, X_train, y_train, X_test, y_test)
plt.show()
结果如下:
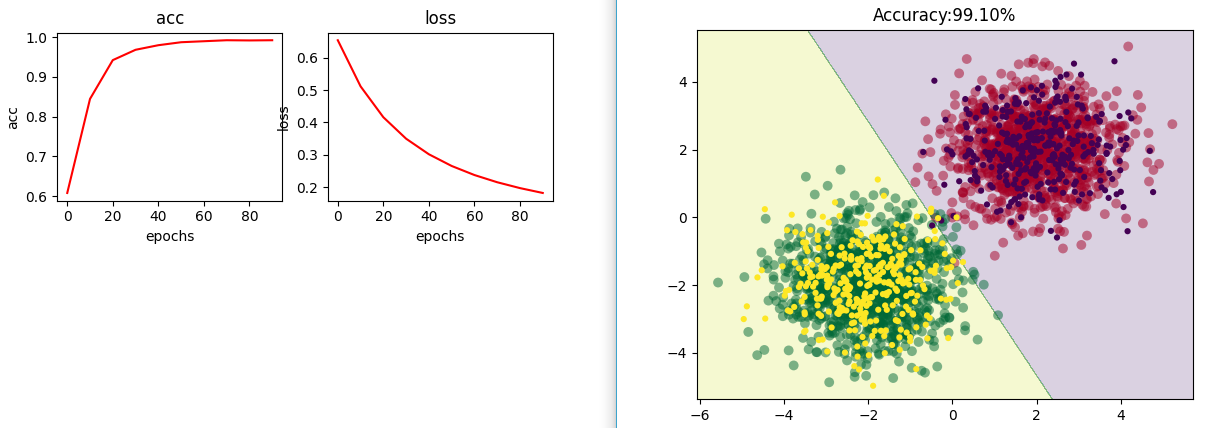
由图可见这种模式实现的模型一样能够很好的分类数据集,同时精度的提升过程和损失下降过程更加平滑。
逻辑回归多分类问题
到目前为止,我们已经介绍了逻辑回归的算法原理,并亲自推导了整个过程,然后从零实现了一遍代码,并在模拟的数据集上进行了算法效果的验证,然后又用torch自带的函数简化实现了LR。 到这里,你已经完整掌握了逻辑回归了,不过仍旧有一个问题,上面实现的代码,我们只能处理二分类的问题,如果要处理多分类,怎么办呢?下面我们就来介绍两种思路,在逻辑回归上实现多分类模型。
ONE vs ALL
第一种实现多分类的思想称之为ONE-VS-ALL,也就是在分类时我们会训练多个分类器,每次把样本划分为label-X及其他,比如对于三分类问题,我们会训练三个分类器,第一个分类器进行(1)-(2,3)的分类,第二个分类器进行(2)-(1,3)的分类,第三个分类器进行(3)-(1,2)的分类,用图例表示为: 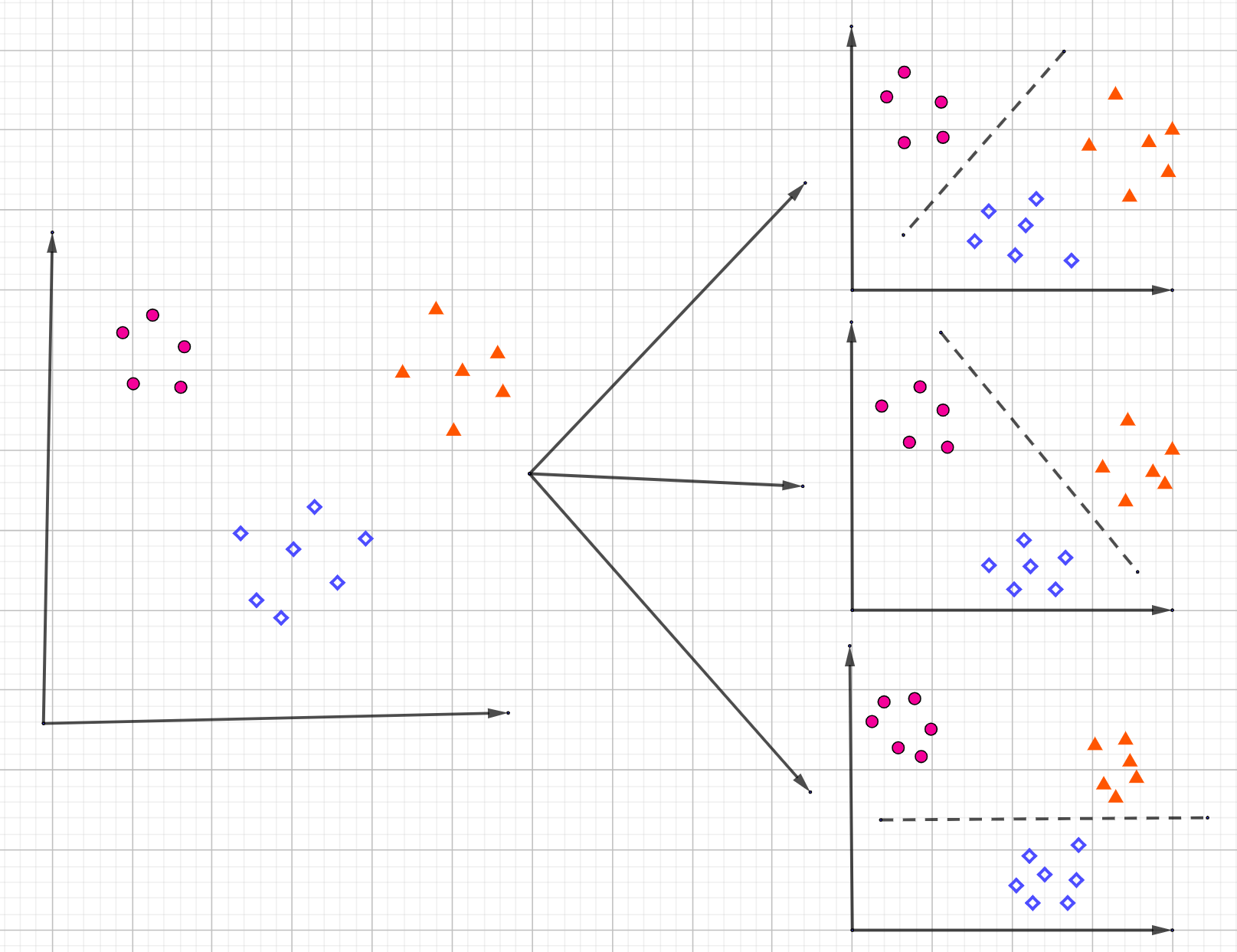 基于这个原理,我们来实现代码:
基于这个原理,我们来实现代码:
class MultiLR:
"""多分类LR"""
def __init__(self):
self.models = []
self.labels = []
def fit(self, X, y, lr=0.1, epochs=100, echo=False):
"""训练模型"""
self.labels = y.unique() # 不同类别
# OVA ONE-VS-ALL
for label in self.labels:
ycp = torch.clone(y)
idx = torch.where(ycp == label)[0]
jdx = torch.where(ycp != label)[0]
ycp[idx] = 1.0
ycp[jdx] = 0.0
net = LR()
net.fit(X, ycp, num_epochs=epochs, lr=lr, echo=echo)
self.models.append(net)
def predict(self, X):
"""预测"""
# 投票
vote = torch.zeros((X.shape[0], len(self.labels)))
for label, model in zip(self.labels, self.models):
y_pred = model.predict(X).reshape(-1)
# 预测为当前类
idx = torch.where(y_pred == 1.0)[0]
vote[idx, int(label)] += 1
# 预测为其他类
ridx = torch.where(y_pred != 1.0)[0]
cidx = torch.tensor([j for j in range(len(self.models)) if j != label.numpy()])
row, col = torch.meshgrid(ridx, cidx, indexing='ij')
vote[row, col] += 1
return torch.argmax(vote, dim=1)
def accuracy(self, X, y):
"""准确率"""
return torch.sum(self.predict(X) == y.reshape(-1)) / len(y)
三分类数据集
在验证模型之前,我们需要生成一份三分类的数据集:
def load_data_n3(size):
"""加载数据:生成虚拟多分类数据"""
num_featurs = 2
X0 = torch.normal(5, 1.3, (size, num_featurs))
y0 = torch.zeros((size, 1))
X1 = torch.normal(0, 1.2, (size, num_featurs))
X1[:, 1] -= 2
y1 = torch.ones((size, 1))
X2 = torch.normal(0, 1.4, (size, num_featurs))
X2[:, 0] -= 4
X2[:, 1] += 4
y2 = 2 * torch.ones((size, 1))
X = torch.cat((X0, X1, X2), dim=0)
y = torch.cat((y0, y1, y2), dim=0)
return X, y
可视化一下数据:
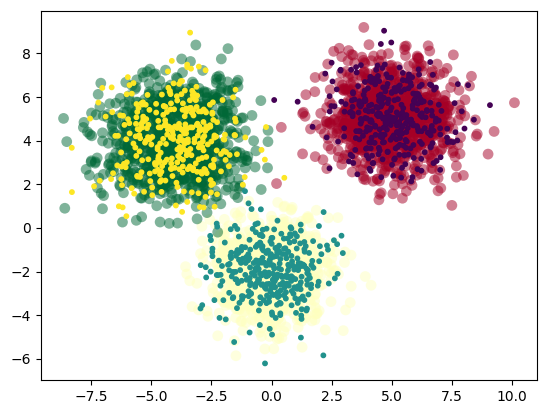
现在可以用这个数据来训练我们的模型了:
X_train, y_train = load_data_n3(num_samples)
X_test, y_test = load_data_n3(num_samples//3)
# 添加偏置b: X = [1 X]
X_train = torch.cat([torch.ones((X_train.shape[0], 1)), X_train], dim=1)
X_test = torch.cat([torch.ones((X_test.shape[0], 1)), X_test], dim=1)
# 可视化数据,二维
plt.figure()
plt.scatter(X_train[:,1], X_train[:,2], c=y_train.numpy(), s=60, lw=0, cmap='RdYlGn', alpha=0.5)
plt.scatter(X_test[:,1], X_test[:,2], c=y_test.numpy(), s=10, lw=1, alpha=1)
mlr = MultiLR()
mlr.fit(X_train, y_train, lr=0.05, epochs=100)
acc = mlr.accuracy(X_test, y_test)
print('OVA model 测试集准确率:', acc.numpy())
plot_decision_boundary(mlr, X_train, y_train, X_test, y_test)
plt.show()
看看模型的效果:
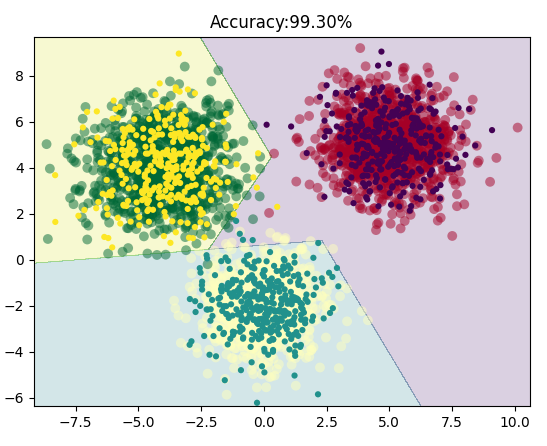
同样,我们的模型对于三分类的数据集依旧分类的很好。
ONE-VS-ONE
上面的这种实现方式有个非常大的不足,当存在多个分类的时候训练每个单独的二分类器时数据集会极度不平衡。而这里介绍的ONE-VS-ONE模型就能克服这种不足,该模型的思想是对于n分类的数据集,每次取出任意两个分类的数据集进行训练生成一个二分类模型,这样一共会生成
class MultiOVOLR:
"""多分类LR"""
def __init__(self):
self.models = []
self.labels = []
def fit(self, X, y, lr=0.1, epochs=100, echo=False):
"""训练模型"""
self.labels = y.unique() # 不同类别
# OVO ONE-VS-ONE
n = 0
for l1, l2 in combinations(self.labels, 2):
n += 1
i = torch.where(y == l1)[0]
j = torch.where(y == l2)[0]
idx = torch.cat([i, j], dim=0)
ycp = torch.clone(y)
ycp[i] = 1.0
ycp[j] = 0.0
net = LR()
net.fit(X[idx, :], ycp[idx], num_epochs=epochs, lr=lr, echo=echo)
self.models.append(net)
def predict(self, X):
"""预测"""
vote = torch.zeros((X.shape[0], len(self.labels)))
for (l1, l2), model in zip(combinations(self.labels, 2), self.models):
y_pred = model.predict(X).reshape(-1)
# 预测为当前类
idx = torch.where(y_pred == 1.0)[0]
vote[idx, int(l1)] += 1
jdx = torch.where(y_pred != 1.0)[0]
vote[jdx, int(l2)] += 1
return torch.argmax(vote, dim=1)
def accuracy(self, X, y):
"""准确率"""
return torch.sum(self.predict(X) == y.reshape(-1)) / len(y)
然后我们来训练模型:
molr = MultiOVOLR()
molr.fit(X_train, y_train, lr=0.05, epochs=100)
acc = molr.accuracy(X_test, y_test)
print('OVO model 测试集准确率:', acc.numpy())
plot_decision_boundary(mlr, X_train, y_train, X_test, y_test)
plt.show()
看看效果如何:
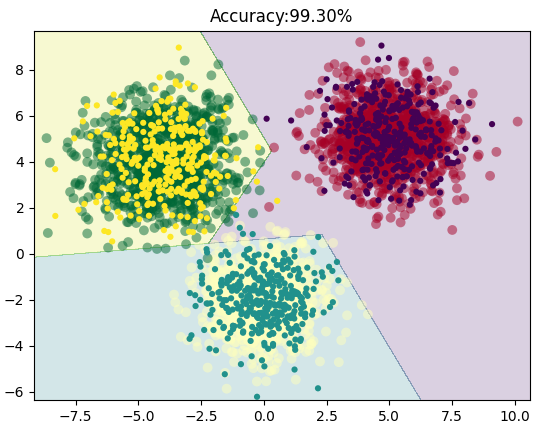
效果同样非常不错!
总结
本文中,我们先推导了逻辑回归的公式,梯度下降过程;然后使用torch从零开始实现了一个LR model,接着使用torch自带函数来简化实现过程;然后在二分类数据集上演示了模型的训练效果。 最后我们介绍了两种在LR模型上使用多分类的思想,分别是ONE-vs-ALL和ONE-vs-ONE,并实现了这两种算法,在三分类数据集上测试了这两种方法,从结果来看效果都非常好。