Python爬虫采集
小于 1 分钟
陈旸老师极客时间《数据分析实战45讲》笔记
爬虫的流程
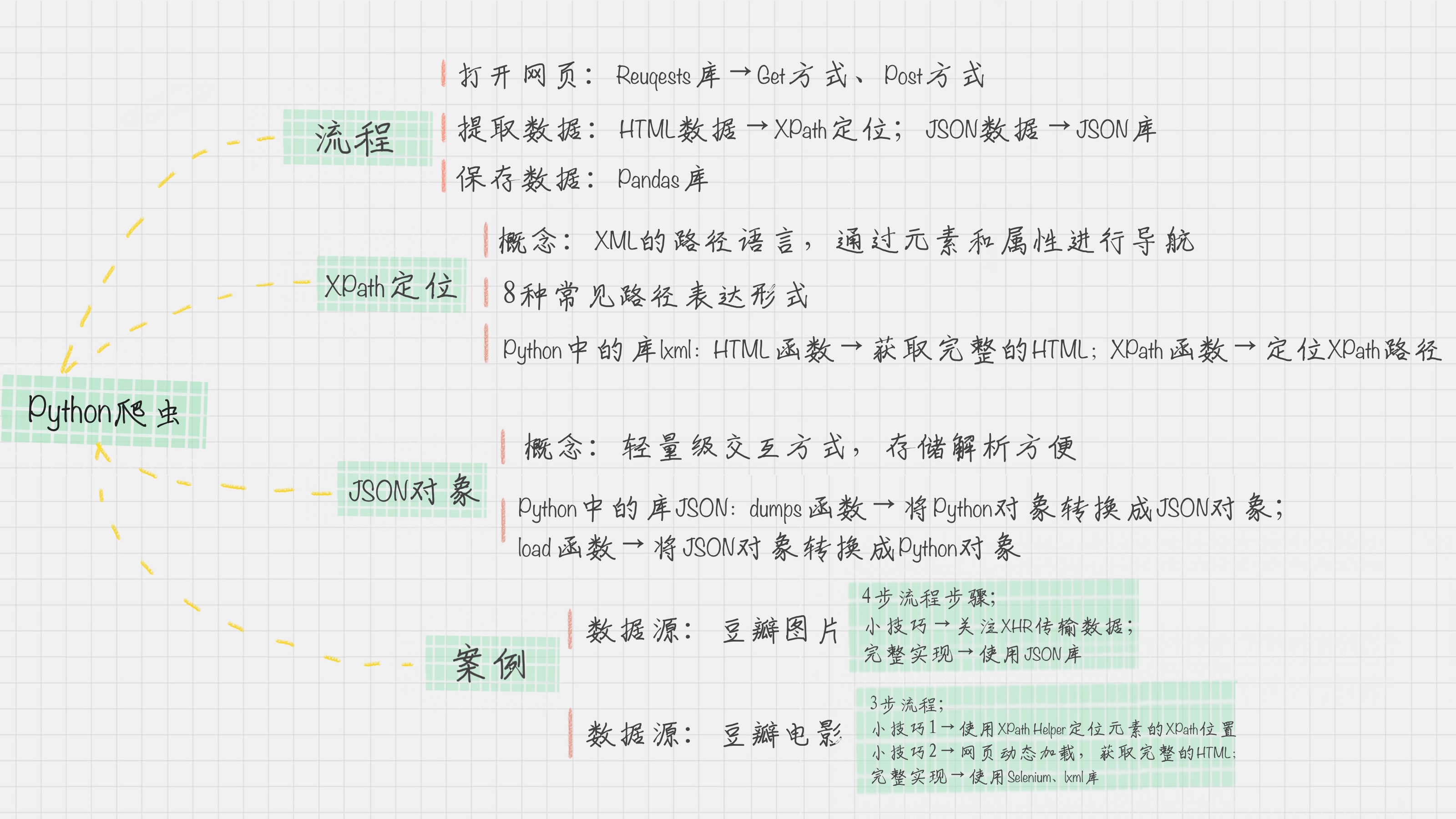
整个过程包括三个阶段:打开网页、提取数据和保存数据。
在 Python 中,这三个阶段都有对应的工具可以使用。
- 在“打开网页”这一步骤中,可以使用 Requests 访问页面,得到服务器返回给我们的数据,这里包括 HTML 页面以及 JSON 数据。
- 在“提取数据”这一步骤中,主要用到了两个工具。针对 HTML 页面,可以使用 XPath 进行元素定位,提取数据;针对 JSON 数据,可以使用 JSON 进行解析。
- 在最后一步“保存数据”中,我们可以使用 Pandas 保存数据,最后导出 CSV 文件。
Selenium 是 Web 应用的测试工具,可以直接运行在浏览器中,它的原理是模拟用户在进行操作,支持当前多种主流的浏览器。