数据变换
陈旸老师极客时间《数据分析实战45讲》笔记
数据变换在数据分析中的角色
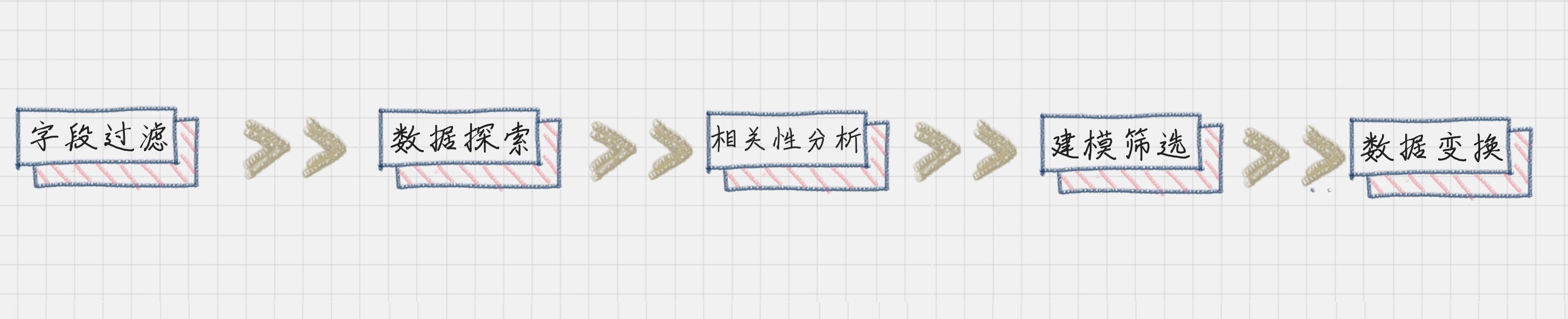
在数据变换前,我们需要先对字段进行筛选,然后对数据进行探索和相关性分析,接着是选择算法模型,然后针对算法模型对数据的需求进行数据变换,从而完成数据挖掘前的准备工作。
所以你从整个流程中可以看出,数据变换是数据准备的重要环节,它通过数据平滑、数据聚集、数据概化和规范化等方式将数据转换成适用于数据挖掘的形式。
**数据平滑:**去除数据中的噪声,将连续数据离散化。这里可以采用分箱、聚类和回归的方式进行数据平滑,我会在后面给你讲解聚类和回归这两个算法;
**数据聚集:**对数据进行汇总,在 SQL 中有一些聚集函数可以供我们操作,比如 Max() 反馈某个字段的数值最大值,Sum() 返回某个字段的数值总和;
**数据概化:**将数据由较低的概念抽象成为较高的概念,减少数据复杂度,即用更高的概念替代更低的概念。
**数据规范化:**使属性数据按比例缩放,这样就将原来的数值映射到一个新的特定区域中。常用的方法有最小—最大规范化、Z—score 规范化、按小数定标规范化等
**属性构造:**构造出新的属性并添加到属性集中。
数据规范化的几种方法
Min-max 规范化
Min-max 规范化方法是将原始数据变换到 [0,1] 的空间中。用公式表示就是:$$x=\frac{x-min(x)}{max(x)-min(x)}$$
Z-Score 规范化:
小数定标规范化:小数定标规范化就是通过移动小数点的位置来进行规范化。小数点移动多少位取决于属性 A 的取值中的最大绝对值。
使用Python 的 SciKit-Learn 库
SciKit-Learn 是 Python 的重要机器学习库,它帮我们封装了大量的机器学习算法,比如分类、聚类、回归、降维等。此外,它还包括了数据变换模块。
我现在来讲下如何使用 SciKit-Learn 进行数据规范化。
Min-max 规范化
from sklearn import preprocessing import numpy as np X=np.random.randn(100,128)*20 print("Origin data shape:",X.shape) print("Origin data max:",X.max()) print("Origin data min:",X.min()) X_minmax = preprocessing.MinMaxScaler().fit_transform(X) print("Norm data shape:",X_minmax.shape) print("Norm data max:",X_minmax.max()) print("Norm data min:",X_minmax.min())Z-Score规范化
from sklearn import preprocessing import numpy as np X=np.random.randn(100,128)*20 print("Origin data shape:",X.shape) print("Origin data max:",X.max()) print("Origin data min:",X.min()) X_zscore = preprocessing.scale(X) print("Norm data shape:",X_zscore.shape) print("Norm data max:",X_zscore.mean()) print("Norm data min:",X_zscore.std())
数据挖掘中数据变换比算法选择更重要
在数据变换中,重点是如何将数值进行规范化,有三种常用的规范方法,分别是 Min-Max 规范化、Z-Score 规范化、小数定标规范化。其中 Z-Score 规范化可以直接将数据转化为正态分布的情况,当然不是所有自然界的数据都需要正态分布,我们也可以根据实际的情况进行设计,比如取对数 log,或者神经网络里采用的激励函数等。
